If you’re reading this blog, chances are, you’re familiar with Git, version control and some general basics of code branching and, as a refresher, let’s take a look at local vs remote repositories, and some basics around code branching.
Software development really is a team sport, and it’s so important for any team to be playing together, not just on the same court. Git allows us to do this through distributed version control, integrated communication and change tracking. Essentially, we store code centrally (on a host such as GitHub or Bitbucket) along with the code’s revision history, and the team can individually bring a copy (“clone”) of that repository down locally and work on it independently. To read more about managing repositories, and cloning read on here:
This is essentially what the process looks like:
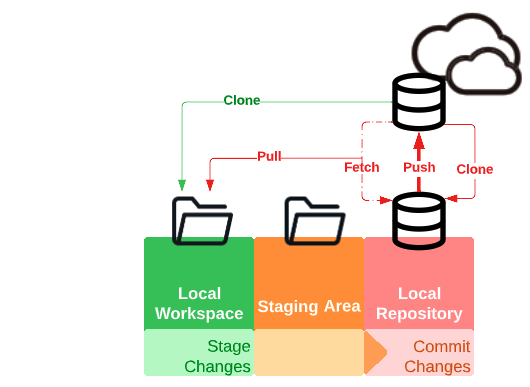
- Fetch a copy of the remote repository to work on locally
- Checkout the branch to begin making changes, and before we make any changes
- Push the new branch to the remote repository so the chain is complete
In Git, when we do the first push, we need to ensure we set the remote like this:
$ git checkout -b mynewlocalbranch
$ git push -set-upstream myupstreambranch
If we miss the option -set-upstream, Git will not define the remote and we get that annoying fatal error
“the current branch <branch> has no upstream branch” D’oh!
Well, good news! As of Git version 2.37.0 we can now update our Git config to autoSetupRemote. (If you haven’t updated in a while you can get the latest version here: https://git-scm.com/). With this simple command we are good to go.
git config –global –add –bool push.autoSetupRemote true
The first-time push to new branches will now automatically set the default remote. It’s a little thing but definitely worth 30 secs of our time to save countless facepalms.



