This article is the first article in our Knowledge Mining with Azure Cognitive Search series that focuses on the cost-effective, modern, new capabilities with AI, knowledge mining, and search on Azure Cognitive Search.
Overview
Here’s an example scenario:
Contoso is a new company in an old business. They provide a full range of insurance services. They use an existing Windows Forms application, with an on-premises SQL Server and an on-premises file server, for management of stakeholders, policies, and documentation. They have a big corpus of documentation – a broad mix of digitised and electronic documents and files – that they’re wanting to process in Azure to begin to make it searchable from their line-of-business application.
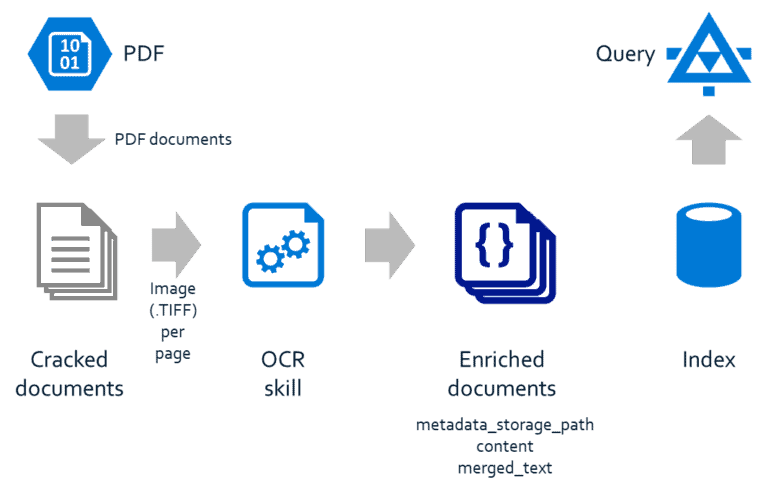
Azure Cognitive Search enables businesses like Contoso deploy AI across their organisational content in order to unlock untapped, unstructured, or semi-structured information. Azure Cognitive Search includes built-in and custom cognitive skills, such as facial recognition, key phrase extraction, and sentiment analysis, that can be applied to content using the cognitive search pipeline. The cognitive search pipeline supports extraction of content from documents, enrichment of it through the cognitive skills, and indexing of it for search.

This article describes how to implement an Azure Cognitive Search pipeline for a collection of clinical trials documents using the Azure CLI, ARM deployments, and the Azure Cognitive Search API.
Prerequisites
- Access to an Azure subscription
- The current version of the Azure CLI
Deploy Azure Cognitive Search
This section describes how to deploy Azure Cognitive Search including how to:
- Create a resource group in which Azure Cognitive Search will be deployed
- Create a storage account in which the clinical trials documents will be uploaded
- Create an Azure Cognitive Search service in which the Azure Cognitive Search pipeline will be implemented in the next section
Create a resource group
The following command creates a resource group called clinicaltrials in which Azure Cognitive Search will be deployed later.
az group create -l australiaeast -n clinicaltrials
Create a storage account
The following command creates a storage account called clinicaltrials, containing a blob container called docs, in which the clinical trials documents will be uploaded in the next step.az group deployment create -g clinicaltrials --template-file .\storage-deploy.json --parameters .\storage-deploy.parameters.json
storage-deploy.json
{
"$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"location": {
"type": "string",
"defaultValue": "[resourceGroup().location]"
},
"storageAccountName": {
"type": "string",
"minLength": 3,
"maxLength": 24
},
"storageAccountSku": {
"type": "string",
"defaultValue": "Standard_LRS",
"allowedValues": [
"Standard_LRS",
"Standard_GRS",
"Standard_RAGRS"
]
}
},
"resources": [
{
"name": "[parameters('storageAccountName')]",
"type": "Microsoft.Storage/storageAccounts",
"apiVersion": "2019-04-01",
"sku": {
"name": "[parameters('storageAccountSku')]"
},
"kind": "BlobStorage",
"location": "[parameters('location')]",
"properties": {
"accessTier": "Hot"
},
"resources": [
{
"name": "[concat('default/', 'docs')]",
"type": "blobServices/containers",
"apiVersion": "2019-04-01",
"dependsOn": [
"[resourceId('Microsoft.Storage/storageAccounts', parameters('storageAccountName'))]"
],
"properties": {
"publicAccess": "None"
}
}
]
}
]
}
storage-deploy.parameters.json
{
"$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentParameters.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"storageAccountName": {
"value": "clinicaltrials"
},
"storageAccountSku": {
"value": "Standard_LRS"
}
}
}
Upload the clinical trials documents
Unpack and then upload the clinical trials documents from this GitHub repository to the blob container that was created in the previous step using the Azure portal, Azure Storage Explorer, or another third-party tool.
Create the Azure Cognitive Search service
The following command creates an Azure Cognitive Search service in which the Azure Cognitive Search pipeline will be implemented in the next section.
az group deployment create -g clinicaltrials --template-file .\Search-deploy.json --parameters .\search-deploy.parameters.json
search-deploy.json
{
"$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"location": {
"type": "string",
"defaultValue": "[resourceGroup().location]"
},
"searchServiceName": {
"type": "string",
"minLength": 2,
"maxLength": 60
},
"searchServiceSku": {
"type": "string",
"defaultValue": "standard",
"allowedValues": [
"free",
"basic",
"standard",
"standard2",
"standard3"
]
},
"searchServiceReplicaCount": {
"type": "int",
"defaultValue": 1,
"minValue": 1,
"maxValue": 12
},
"searchServicePartitionCount": {
"type": "int",
"defaultValue": 1,
"allowedValues": [
1,
2,
3,
4,
6,
12
]
},
"searchServiceHostingMode": {
"type": "string",
"defaultValue": "default",
"allowedValues": [
"default",
"highDensity"
]
}
},
"resources": [
{
"name": "[parameters('searchServiceName')]",
"type": "Microsoft.Search/searchServices",
"apiVersion": "2015-08-19",
"location": "[parameters('location')]",
"properties": {
"replicaCount": "[parameters('searchServiceReplicaCount')]",
"partitionCount": "[parameters('searchServicePartitionCount')]",
"hostingMode": "[parameters('searchServiceHostingMode')]"
},
"sku": {
"name": "[toLower(parameters('searchServiceSku'))]"
}
}
]
}
search-deploy.parameters.json
{
"$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentParameters.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"searchServiceName": {
"value": "clinicaltrials"
},
"searchServiceSku": {
"value": "free"
},
"searchServiceReplicaCount": {
"value": 1
},
"searchServicePartitionCount": {
"value": 1
},
"searchServiceHostingMode": {
"value": "default"
}
}
}
Implement an Azure Cognitive Search pipeline
This section describes how to implement an Azure Cognitive Search pipeline including how to:
- Create a data source resource that represents the “input” for an Azure Cognitive Search pipeline
- Create a skillset resource that represents a collection of skills that enrich content in an Azure Cognitive Search pipeline
- Create an index resource that represents the “output” for an Azure Cognitive Search pipeline
- Create an indexer resource that represents a configuration of the data source, skillset, and index resources for an Azure Cognitive Search pipeline
Get an admin key
The following command gets the admin keys (i.e. a primary admin key and a secondary one) for use with the Azure Cognitive Search API.
az search admin-key show -g clinicaltrials --service-name clinicaltrials
Create a data source resource
A data source resource represents one of the following “inputs” for an Azure Cognitive Search pipeline: The following command creates a data source resource called docs that refers to the storage account that was created earlier. 1. Use POST and the following URL to create the data source resource:POST https://clinicaltrials.search.windows.net/datasources?api-version=2019-05-06
Content-Type: application/json
api-key: <admin-key>
where api-key is one of the admin keys that was gotten in the previous step.
2. Use the following request body to specify properties for the data source resource:
{
"name": "docs",
"type": "azureblob",
"credentials": {
"connectionString": "<connection-string>"
},
"container": {
"name": "docs"
}
}
where connection-string is either the access key for the storage account or a shared access signature (SAS) token for either the storage account or the blob container (recommended).
Note: If you use a SAS token, then it must generated with the (l)ist and (r)ead permissions.
The POST command returns a 201 Created response such as:
201 Created
Content-Type: application/json; odata.metadata=minimal
{
"@odata.context": "https://clinicaltrials.search.windows.net/$metadata#datasources/$entity",
"@odata.etag": "\"0x8D7AD298817B3C9\"",
"name": "clinicaltrialsfiles",
...
}
Create a skillset resource
A skillset resource represents a collection of built-in skills (e.g. image analysis, OCR, and text analysis), custom skills, or a mix of both that enrich content in an Azure Cognitive Search pipeline.
The following command creates a skillset resource called ocr containing the following skills:
- The Optical Character Recognition (OCR) skill that extracts the printed and handwritten text in a clinical trials document.
- The Text Merge skill that merges both the embedded text and the extracted text in a clinical trials document into a single field.
1. Use POST and the following URL to create the skillset resource:
POST https://clinicaltrials.search.windows.net/skillsets?api-version=2019-05-06
Content-Type: application/json
api-key: <admin-key>
where api-key is one of the admin keys that was gotten earlier.
2. Use the following request body to specify properties for the skillset resource:
{
"name": "ocr",
"skills": [
{
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "text",
"targetName": "text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.MergeSkill",
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/content"
},
{
"name": "itemsToInsert",
"source": "/document/normalized_images/*/text"
},
{
"name": "offsets",
"source": "/document/normalized_images/*/contentOffset"
}
],
"outputs": [
{
"name": "mergedText",
"targetName": "merged_text"
}
]
}
]
}
The POST command returns a 201 Created response such as:
201 Created
Content-Type: application/json; odata.metadata=minimal
{
"@odata.context": "https://clinicaltrials.search.windows.net/$metadata#skillsets/$entity",
"@odata.etag": "\"0x8D7AD3365AF5CAC\"",
"name": "ocr",
...
}
Create an index resource
An index resource represents the “output” for an Azure Cognitive Search pipeline. The following command creates an index resource called master containing the following fields.| Name | Description | Type | Searchable |
| id | Key. | Edm.String | Yes |
| url | The absolute URI for a clinical trials document. | Edm.String | No |
| metadata_storage_name | The name of a clinical trials document. | Edm.String | No |
| metadata_storage_content_type | The content type of a clinical trials document. | Edm.String | No |
| metadata_storage_size | The size of a clinical trials document. | Edm.Int64 | No |
| metadata_storage_last_modified | When a clinical trials document was last modified. | Edm.DateTimeOffset | No |
| content | The embedded text for a clinical trials document. | Edm.String | Yes |
| merged_text | The embedded and extracted text for a clinical trials document. | Edm.String | Yes |
1. Use POST and the following URL to create the index resource:
POST https://clinicaltrials.search.windows.net/indexes?api-version=2019-05-06
Content-Type: application/json
api-key: <admin-key>
where api-key is one of the admin keys that was gotten earlier.
2. Use the following request body to specify properties for the skillset resource:
{
"name": "master",
"fields": [
{
"name": "id",
"type": "Edm.String",
"filterable": false,
"sortable": false,
"facetable": false,
"key": true
},
{
"name": "url",
"type": "Edm.String",
"searchable": false,
"filterable": false,
"sortable": false,
"facetable": false
},
{
"name": "metadata_storage_name",
"type": "Edm.String",
"searchable": false,
"filterable": false,
"sortable": false,
"facetable": false
},
{
"name": "metadata_storage_content_type",
"type": "Edm.String",
"searchable": false,
"filterable": false,
"sortable": false,
"facetable": false
},
{
"name": "metadata_storage_size",
"type": "Edm.Int64",
"searchable": false,
"filterable": false,
"sortable": false,
"facetable": false
},
{
"name": "metadata_storage_last_modified",
"type": "Edm.DateTimeOffset",
"searchable": false,
"filterable": false,
"sortable": false,
"facetable": false
},
{
"name": "content",
"type": "Edm.String",
"filterable": false,
"sortable": false,
"facetable": false
},
{
"name": "merged_text",
"type": "Edm.String",
"filterable": false,
"sortable": false,
"facetable": false
}
]
}
The POST command returns a 201 Created response such as:
201 Created
Content-Type: application/json; odata.metadata=minimal
{
"@odata.context": "https://clinicaltrials.search.windows.net/$metadata#indexes/$entity",
"@odata.etag": "\"0x8D7AD3368AEFD9A\"",
"name": "master",
...
}
Create an indexer resource
An indexer resource represents a configuration of the data source, skillset, and index resources for an Azure Cognitive Search pipeline. The following command creates an indexer resource called docs-ocr-master that refers to the following resources that were created in the previous steps:- The docs data source resource
- The ocr skillset resource
- The master index resource
POST https://clinicaltrials.search.windows.net/indexers?api-version=2019-05-06
Content-Type: application/json
api-key: <admin-key>
where api-key is one of the admin keys that was gotten earlier.
2. Use the following request body to specify the properties for the indexer resource:
{
"name": "docs-ocr-master",
"dataSourceName": "docs",
"targetIndexName": "master",
"skillsetName": "ocr",
"parameters": {
"batchSize": 1,
"configuration": {
"imageAction": "generateNormalizedImages"
}
},
"fieldMappings": [
{
"sourceFieldName": "metadata_storage_path",
"targetFieldName": "id",
"mappingFunction": {
"name": "base64Encode"
}
},
{
"sourceFieldName": "metadata_storage_path",
"targetFieldName": "url"
}
],
"outputFieldMappings": [
{
"sourceFieldName": "/document/merged_text",
"targetFieldName": "merged_text"
}
]
}
The POST command returns a 201 Created response such as:
201 Created
Content-Type: application/json; odata.metadata=minimal
{
"@odata.context": "https://clinicaltrials.search.windows.net/$metadata#indexers/$entity",
"@odata.etag": "\"0x8D7AD3377554FFE\"",
"name": "docs-ocr-master",
...
}
Run the Azure Cognitive Search pipeline
This section describes how to run the Azure Cognitive Search pipeline that was implemented in the previous section.
1. Use POST and the following URL to run the Azure Cognitive Search pipeline:
POST https://clinicaltrials.search.windows.net/indexers/docs-ocr-master/run?api-version=2019-05-06
api-key: <admin-key>
The POST command returns a 202 Accepted response such as:
202 Accepted
3. Then use GET and the following URL to check for the execution status the Azure Cognitive Search pipeline that was run in the previous step:
GET https://clinicaltrials.search.windows.net/indexers/docs-ocr-master/status?api-version=2019-05-06
api-key: <admin-key>
The GET command returns a 200 OK response containing the last and previous results, such as:
200 OK
Content-Type: application/json; odata.metadata=minimal
{
"@odata.context": "https://clinicaltrials.search.windows.net/$metadata#Microsoft.Azure.Search.V2019_05_06.IndexerExecutionInfo",
"name": "docs-ocr-master",
"status": "running",
"lastResult": {
"status": "transientFailure",
"errorMessage": "Indexing was stopped because the free skillset execution quota has been reached. When no cognitive services subscription is attached to a skillset, only 20 documents can be enriched at a time. To index more documents, attach a cognitive services subscription to your skillset. See https://aka.ms/cog-srch-attach for more information.",
"startTime": "2020-02-11T11:06:22.558Z",
"endTime": "2020-02-11T11:06:38.549Z",
"itemsProcessed": 20,
"itemsFailed": 0,
...
},
"executionHistory": [
...
]
}
Note: As per the above error, skillsets for an Azure Cognitive Search pipeline are free for a small workload, but they must be attached to an Azure Cognitive Search resource for a larger workload.
Test the Azure Cognitive Search pipeline
This section describes how to test the Azure Cognitive Search pipeline that was implemented earlier.
Get a query key
The following command gets the query keys for use with the Azure Cognitive Search API.
az search query-key list -g clinicaltrials --service-name clinicaltrials
Query the Azure Cognitive Search index
1. Use GET and the following URL to query the collection of documents in the master index that was created earlier:
GET https://clinicaltrials.search.windows.net/indexes/master/docs?api-version=2019-05-06&?search=Morquio
Content-Type: application/json
api-key: The GET command returns a 200 OK response such as:
HTTP/1.1 200 OK
{
"@odata.context": "https://.search.windows.net/indexes('master')/$metadata#docs(*)",
"value": [
{
"@search.score": 0.25776404,
"id": "aHR0cHM6Ly9jbGluaWNhbHRyaWFscy5ibG9iLmNvcmUud2luZG93cy5uZXQvZmlsZXMvSUNUMDE1MTU5NTYucGRm",
"url": "https://clinicaltrials.blob.core.windows.net/files/ICT01515956.pdf",
"metadata_storage_name": "ICT01515956.pdf",
"metadata_storage_content_type": "application/pdf",
"metadata_storage_size": 76451,
"metadata_storage_last_modified": "2020-02-09T06:31:25Z",
"content": "\n \n\n[image: image0.jpg]\n\n\n",
"merged_text": "\n \n\n[image: image0.jpg] Study of BMN 110 in Pediatric Patients < 5 Years of Age With Mucopolysaccharidesis IVA (Morquio A Syndrome) This open-label Phase 2 study will evaluate the safety and efficacy of weekly 2.0 mg/kg/wk infusions of BMN 110 in pediatric patients, less than 5 years of age at the time of administration of the first dose of study drug, diagnosed with MPS IVA (Morquio A Syndrome) for up to 208 weeks. \n\n\n"
}
]
}Conclusion
Businesses across industries – including healthcare, legal, and manufacturing – are looking for cost-effective, modern, new capabilities with AI, knowledge mining, and search on a cloud service.
Azure Cognitive Search is the one and only cloud search service containing these AI, knowledge mining, and search capabilities for enrichment of content at scale.
For more information about Azure Cognitive Search, see the Azure Cognitive Search documentation.
About Arinco
Arinco as a Microsoft Partner has developed a Knowledge Mining professional service offering for extracting unstructured content from documents (such as Word, PDF, and JPEG), enriching it through skills (such as key phrases), and indexing it for search and then integrating this into the development and operations (devops) toolchain.
This service offering targets customers across industries who have a big corpus of documentation – such as a broad mix of digitised and electronic documents and files – that they’re wanting to process in Azure to begin to make it searchable from their line-of-business applications.
For more information about the service offering, download our Knowledge Mining datasheet or reach us via the Arinco website.






