
When Fabric deploys all pipelines at once, any pipeline that references another pipeline (e.g. calls it via the Invoke Pipeline activity) can fail if its dependency isn’t deployed first. This results in broken references and error messages like the one below. Microsoft Fabric pipeline deployment order is crucial for DevOps workflows, especially when multiple pipelines depend on each other. If you’ve tried syncing multiple interdependent pipelines from a Git repo into a Microsoft Fabric workspace, you’ve likely discovered a major gap: there is no native way to specify the Microsoft Fabric Pipeline Deployment Order.
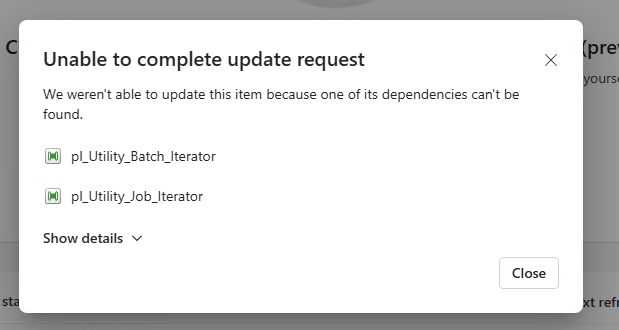
In this post, we’ll walk through a manual workaround, why it’s so fragile, and how you can help push for an official solution by upvoting and sharing feedback with Microsoft.
Why Microsoft Fabric pipeline deployment order Matters
In many data engineering and DevOps scenarios, pipelines call each other, pass parameters, or rely on a shared resource. If you bring them all into a new Fabric workspace simultaneously, the references to each other’s pipeline IDs can be broken unless everything deploys in a precise, dependency-aware sequence.
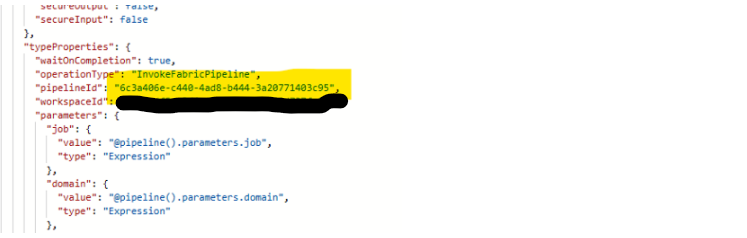
Yet as of today, Fabric’s initial sync from a Git repo does not let you specify an order. Instead, it tries to deploy them all at once.
The Current Workaround (and Why It’s Painful)
1. Temporarily disable auto-deployment for pipelines
Fabric identifies pipeline definitions via .platform metadata files. To prevent a dependent pipeline from deploying too early, you temporarily rename its .platform file (for example, remove the leading dot) so Fabric won’t recognise and deploy it yet. Once you have done this for all pipelines with dependencies, begin your initial repo sync.
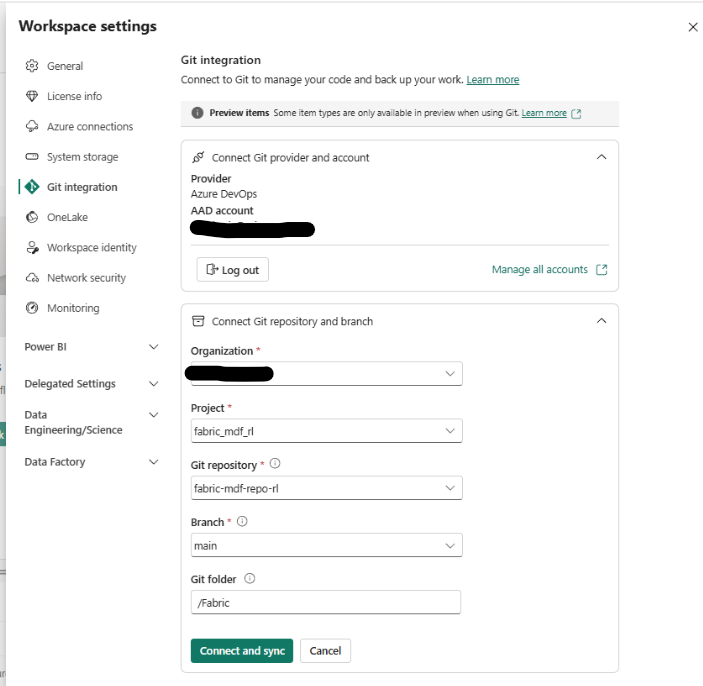
2. Deploy in sequence manually
Determine the correct Microsoft Fabric pipeline deployment order by identifying pipelines with no dependencies first (or act as foundations for others). For example, deploy Pipeline B before Pipeline A if A depends on B. You will bring each pipeline into the workspace one at a time, in the correct sequence. As per the steps 3, 4, 5 and 6.
3. Re-enable and update each pipeline one by one:
For each pipeline you want to deploy rename its platform file back to .platform so that Fabric will recognise this pipeline artifact again. In that pipeline’s folder, open the pipeline-content.json file. Manually update any pipeline reference IDs inside it so they match the correct IDs of the dependant pipelines. You can retrieve a pipeline’s GUID/ID from the URL. This step is crucial if Pipeline A calls Pipeline B you must replace the reference with Pipeline B’s new ID in the current environment.
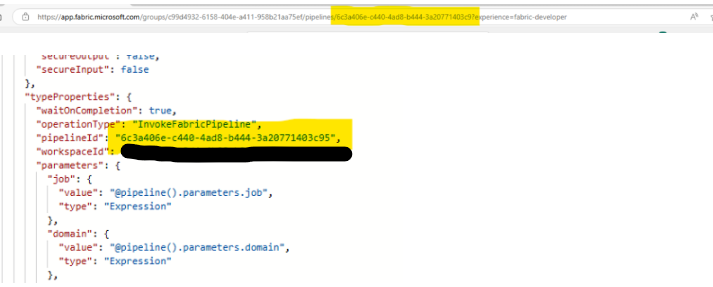
4. Sync the single pipeline to Fabric
In the Fabric workspace connected to Git, perform an Update from the repository for this pipeline. This will create the pipeline in Fabric using the files you just edited. Because you only re-enabled one pipeline’s .platform file, only that pipeline will sync. Verify that it appears in the workspace and that it’s functioning with the correct dependency references.
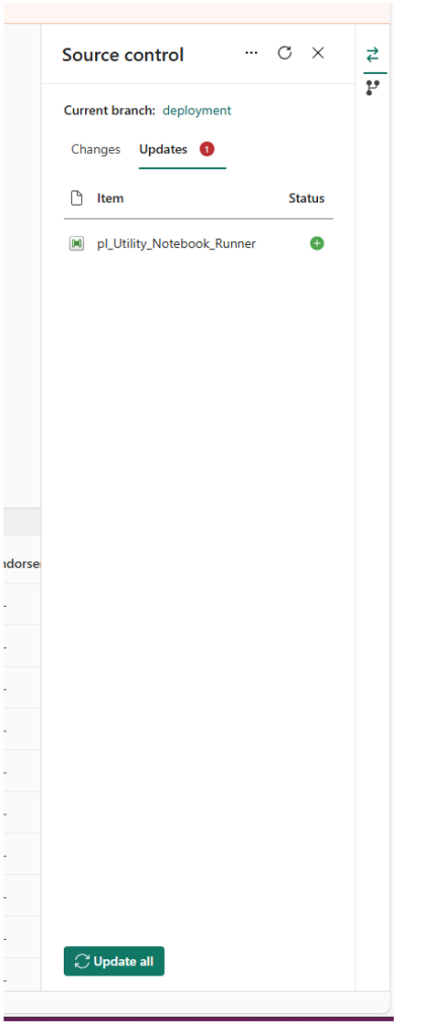
5. Clean up the repository reference
Back in the repository, delete the pipeline’s folder (the one you just synced) from the repo. This sounds counterintuitive, but it helps avoid Git conflicts because of the duplicate entries. Essentially, once the pipeline is in the workspace with the correct dependant pipeline ID, you remove the old definition from source control to prepare for a fresh commit of the updated version.
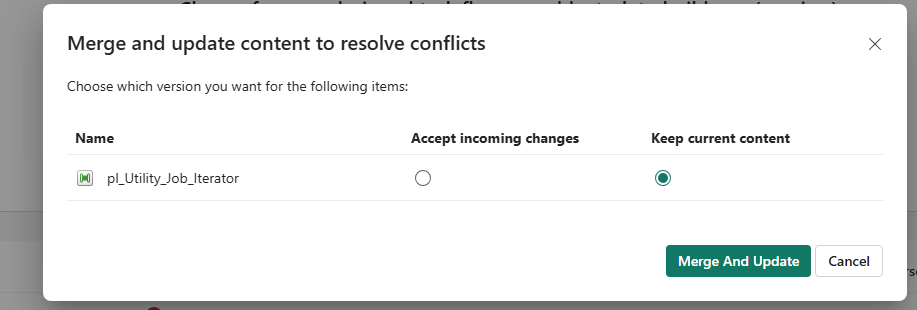
6. Commit the pipeline back to Git
From the Fabric workspace, commit the newly synced pipeline to the repository. When doing this, use the “Keep current content”. This ensures that the version in the repository is now the one that matches the workspace (with updated IDs and all). The pipelines will now work even though the pipeline ID from the URL will not match the pipeline id in the .parameter file.
Why This Approach Is Not Sustainable
Human Error
Renaming files, editing IDs, and re-committing in a strict order is inherently fragile. A single mistake can force you to start over.
Time-Consuming
If you have more than a few pipelines, you’ll spend a lot of time toggling .platform names, copying IDs, and verifying references.
Messy Git History
Deleting and re-adding folders creates noisy commits. Other team members may be confused by these changes, and you can lose track of who did what, when.
Lack of Continuous Integration
True CI/CD thrives on automated deployments that run end-to-end without manual steps. This workaround is anything but automated, so it derails typical DevOps flows.
A Better Way: Configurable Deployment Order
What we really need is for Microsoft Fabric to handle pipeline dependencies automatically or at least allow us to set an order for the initial import.
I have raised an idea to “Enable Configurable Deployment Order for Initial Sync from Repo”. If you’ve faced the same frustration with Microsoft Fabric pipeline deployment order, please upvote and share the idea
Enable Configurable Deployment Order for Initial S… – Microsoft Fabric Community
By rallying behind this request, we show Microsoft that it’s a high-priority need for real-world DevOps scenarios. With enough votes, we can make deployments less fragile and more DevOps-friendly.






