
Welcome to Opinionated Pattern Picking (OPP), a monthly session we run at Arinco to foster an environment of discussion and learning for our application developers and anyone else interested. Each month the team discusses a topic and attempts to elect a “best default” pattern for developers to use on future projects. View the rest of the blog series here.
What solution are we designing for?
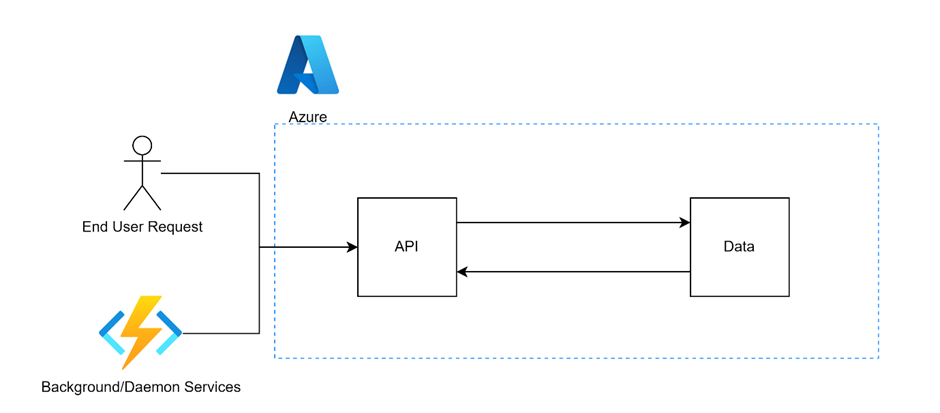
Instead of looking to build an enterprise solution, we take the approach of starting with a straightforward solution: we create a solution that involves an API and some data that can be retrieved either in response to an end-user request or by a daemon service running in the background. This simple approach is still quite detailed, providing us with enough substance to delve into before adding further complexity.
Pattern Picking
What is a Data Model?
The first discussion point this month was about the definition of what a data model is. We have lots of different variations for the names – we have domain models, classes, DTOs, POCOs and ER class or relationship diagrams which can be represented by a database schema.
Let’s start with a Data Transfer Object (DTO). It can be used between layers for the transfer of data. The distinction is that it doesn’t encapsulate any behaviour, only properties. A DTO can be for transferring data between anything – layers within a solution, between solutions, between a UI and backend.
When it comes to the topic of domain models, this sparked significant discussion. There’s a question of whether you are doing DDD or not. We have to consider if we’re talking about a domain model as the model of your domain, or classes within your code that represent things in your domain. Domain models like ubiquitous language and high-level concepts are distinct from implementation, though they’re very similar grammatically and conceptually.
The group emphasized that domain models typically have behaviour, unlike DTOs. However, you could have a domain model without functionality – what’s known as an anemic domain model. You would just have your logic external to it. This led to discussion about whether this should be excluded from the definition. As it started to resemble other more well-established concepts like DTO or plain old class object (POCO)
Cohesion and Coupling
A significant portion of the discussion focused on cohesion and coupling in models as a method to define the properties of models. The definitions as decided in the session were:
Coupling
Coupling refers to the degree of interdependence between software modules. High coupling means that modules are closely connected and changes in one module may affect other modules. Low coupling means that modules are independent and changes in one module have little impact on the other modules
Cohesion
Cohesion refers to the degree to which elements within a module work together to fulfill a single well-defined purpose. High cohesion means that elements are closely related and focused on a single purpose, while low cohesion means that elements are loosely related and serve multiple purposes.
A concrete example shared was a class that sends an email as well as rendering a text box on the UI – this demonstrates very low cohesion as it has two unrelated responsibilities.
The DRY Principle and Its Application
The discussion touched on the DRY (Don’t Repeat Yourself) principle. The key insight was that DRY refers to behaviour and knowledge in particular, for example we don’t repeat domain models that preform the same action E.G send a parcel.
The group emphasised finding a middle ground to prefer duplication of data to the wrong abstraction emerged as an important principle. Sometimes duplicate a method or data is acceptable if the result is a reduction in coupling or a simplification or better distinction of responsibilities between the data model that you are creating.
Database-First vs Code-First modelling
The conversation covered approaches to database interaction. For greenfield projects, the team generally preferred code-first approaches. However, there was recognition that sometimes you encounter scenarios with massive, shared databases where database-first approaches are necessary.
When working with an existing database, you might face “300 column wide tables” where your application only needs a subset of that data. This influences how you structure your entities and models in the application.
Growing and Scaling
Developers start with simpler architectures and evolve them as needed. As one participant noted, they normally start working on a project with a simple stream-lined architecture and then move towards a modular, DDD approach or similar enterprise architecture depending on what suits the project.
The discussion emphasised that this evolution needs to be managed carefully. The importance of maintaining consistency while being open to careful refactoring was highlighted. The group agreed that while starting simple is important, designing with growth in mind is crucial.
Opinionated Pattern Picked
While the group didn’t settle on a single prescriptive approach, there was agreement that discussed above provided a framework to assist in developer decision making. Whilst remaining mindful of the business context we are designing for to keep our applications maintainable and scalable.
The choice depends heavily on various factors including the client’s technical maturity, team structure and communication patterns, project complexity and requirements, and need for future flexibility. Clean architecture provides a safe foundation, Modular Monolith offers flexibility for growth, and DDD concepts can be selectively applied where the additional effort and design can have a tangible return on investment.



